EmisView User’s Guide
Table of Contents
1. Introduction
EmisView is an open-source emissions data quality assurance (QA) software tool that is being developed with funding from the U.S. EPA’s Emissions Inventory Improvement Program (EIIP) along with funding from EPA’s Emission Inventory Group. EmisView supports emissions modeling activities of states, Regional Planning Organizations (RPOs), and EPA. The software reads data used and created by the Sparse Matrix Operator Kernel Emissions (SMOKE) modeling system and the CONsolidated Community Emissions Processing Tool (CONCEPT). EmisView can read the emission inventory data formats used by these two systems, which include the National emission inventory Input Format (NIF3) and Output Format (NOF), Inventory Data Analyzer (IDA), and One Record per Line (ORL) formats. Eventually, EmisView will also be able to read SMOKE and CONCEPT intermediate data at specified stages of processing and to access model-ready output files. For more information on SMOKE, see http://www.cep.unc.edu/empd/products/smoke/version2.1/. For more information on CONCEPT, see http://www.conceptmodel.org.
EmisView will be an integral quality assurance component of EPA’s new Emissions Modeling Framework, which will serve as a data management tool for emissions modeling data, a quality assurance system, and a Graphical User Interface (GUI) for running SMOKE. Wherever possible, EmisView will facilitate the customization of predefined analyses, such as adjusting colors, labels, and axis ranges. It will also facilitate the addition of new analyses by Structured Query Language (SQL) programmers. EmisView will initially focus on criteria pollutants, but the design will allow the software’s use for toxics compounds as well.
EmisView stores and accesses data from the relational databases MySQL (http://www.mysql.com) and PostgreSQL (http://www.postgresql.org). Other relational databases could be supported in the future. EmisView uses the R software environment for statistical computing and graphics to create plots (see http://www.r-project.org/). EmisView is written in Java and has been tested on Linux and Windows. It is likely that EmisView will work on other computing platforms that support Java, MySQL or PostgreSQL, and R. Prior to performing analyses with EmisView, the data files must be imported into EmisView “Datasets”. During the import process, data from ASCII files such as NIF3, ORL, and IDA files are placed into database tables in MySQL or PostgreSQL. If the data are already resident in a MySQL or PostgreSQL database (as they will be for CONCEPT users), the data do not need to be reimported. Instead, an EmisView Dataset can be created by specifying where to find the emissions data in the database.
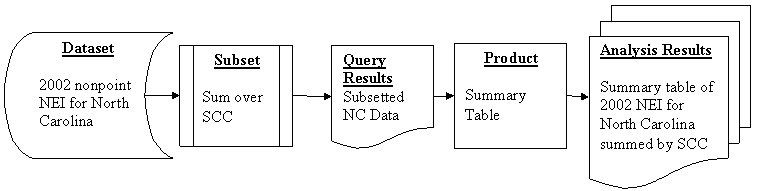
While Datasets provide the input data source for analyses in EmisView, Subsets serve as templates that specify portions of datasets to extract (e.g., the data from specified states) and how to aggregate the data to higher levels (e.g., sum over SCC). Products specify how to present data. Examples of products include tables and nongeographic plots, and eventually geographic plots. Analyses tie together the Datasets, Subsets, and Products to create the analysis results. When an Analysis is run, it creates and executes a query on the database that uses the Dataset as the source of the data and applies the Subset. The results of the query are presented to the user according to the selected Product to create the Analysis Results. A sketch of this process is shown in Figure 1.
Figure
1. Diagram of an Example
EmisView Analysis
A goal of EmisView is that the Subsets and Products be re-usable and be applicable to many different Datasets. The primary Product supported in the initial version of EmisView is the Summary Table and Plots. When this Product is selected, the analysis results appear in an interactive table that supports sorting, filtering, creation of nongeographic plots, and statistical analyses. The tool used for this is the Multimedia Integrated Modeling System (MIMS) Analysis Engine (see http://mimsfw.sourceforge.net and http://www.epa.gov/asmdnerl/Multimedia/MIMS/). The following types of statistical tables can be created by the Anlaysis Engine: basic statistics (e.g., minimum, maximum, mean, standard deviation) histogram, percentiles, regression analysis, and correlation analysis. Eventually, new products that create geographic plots and perform comparative analyses between datasets will be incorporated into EmisView.
The remainder of
this document will help you to get started using EmisView to define and run
Analyses. Some parts of this guide can
be used as a tutorial to help you get started.
The tutorial steps are shown in green.
2. Main GUI
The EmisView Main GUI window allows you to create and access all of the information needed to perform an analysis. Before performing an analysis using EmisView, you first need to create the following items within EmisView:
- At least one Dataset to analyze.
- At least one Subset to specify how to subset and aggregate the data in the dataset.
- At least one Product to show the results of the analysis (e.g., in a table or on a map).
At least one Analysis that specifies a Dataset, Subset, and Product that are combined to create analysis results.
To start EmisView, execute the runEmisView.bat or runEmisView.sh script. This should cause the EmisView Main GUI to appear. On Windows, a black DOS command prompt window will also appear. You may iconify this window (or “send it to the Windows bar”) if you find it distracting, but do not close the window using the X on the window bar, because this will cause EmisView to close.
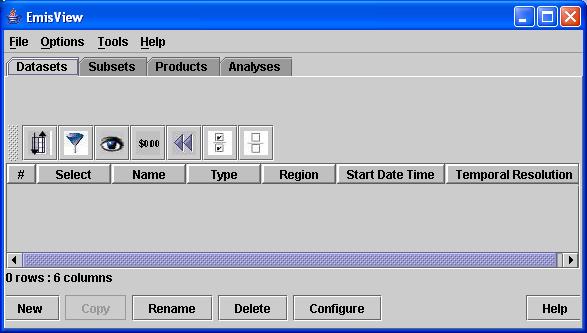
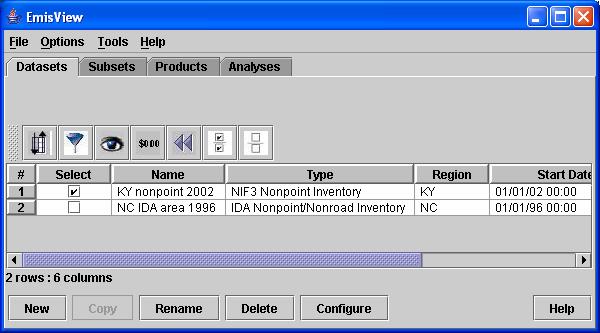
The EmisView Main GUI consists of a menu bar and four tabs: Datasets, Subsets, Products, and Analyses. The Datasets tab shows the datasets that are available from EmisView, the Subsets tab shows the available Subsets, the Products tab shows the available analysis Products, and the Analyses tab shows the available Analyses. The menu bar and each of these tabs are documented in the following sections. Note that some features common to all of the tabs are discussed in the section describing the Datasets tab. Figure 2 shows a screenshot from the Main GUI when you tart EmisView for the first time.
Figure 2. EmisView Main GUI (Datasets Tab)
The menu bar on the Main GUI provides access to the following functions:
- File:
- Import data: Allows you to create new datasets
- Quit: Exits EmisView
- Options:
- Set databases: Allows you to specify the databases used by EmisView (see below for more information)
- Tools:
- Analysis Engine: Brings up the MIMS Analysis Engine for analyzing data files (e.g., Smkreport outputs) directly
- Help:
- Users Guide: Loads the user’s guide in a new window
- About: Provides basic information about EmisView and the version being used
Note that EmisView uses three different types of data schemas (i.e. database table structures) in the user’s relational database to produce the analysis results:
· the emissions data schema stores the emissions data that are the primary data source for Datasets;
· the analysis data schema stores information used by the GUI about the Analyses, metadata for Datasets, Subsets, and Products; and
· the reference data schema contains static reference information such as county names and SCC descriptions.
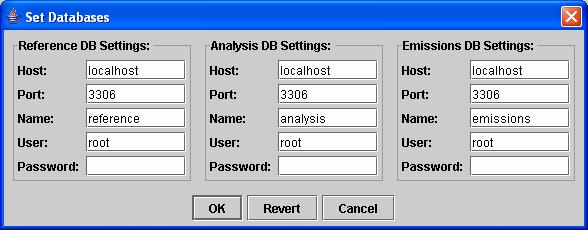
In MySQL these schemas are implemented in separate databases, while in PostgreSQL these data are stored in different schemas within one or two databases. The Set Databases dialog shown in Figure 3 allows you to specify the names of these data schemas and the user name and password information for your database server. Your first opportunity to set this information was during EmisView installation. The information you entered during the installation is stored in the user_preferences.txt file in the bin directory. If you later need to change any of the settings after installation, you may do so from the Set Databases dialog. When you click OK, the user_preferences.txt file will be re-created using your new settings. However, note that if you change your Analysis database, EmisView will not automatically load your Datasets, Subsets, Products, and Analyses stored in the newly specified database. To reload this information, you must exit and then restart EmisView. If you are a CONCEPT user, be sure to set the name of your emissions database in your user_preferences.txt file to the name of the PostgreSQL database that contains your emissions inventories that are accessed by CONCEPT. If you are not a CONCEPT user, the default names provided for the databases should be sufficient.
Figure
3. Set Databases Dialog
3. Datasets
The Datasets tab is a natural place to get started with EmisView, as you cannot run any Analyses until you have some data loaded into Datasets. Instructions for creating Datasets are found in the Importing data into EmisView bullet that follows this paragraph. If you are a CONCEPT user and your data are already in the database, you still need to create an EmisView Dataset that refers to these data. An example of the Datasets tab is shown above in Figure 2. This section discusses the components of the Datasets tab and how to import data into EmisView.
- Importing data into EmisView:
Prior to using data in EmisView, they must be imported (i.e., loaded into
the emissions database).
a. From the Datasets tab, click New (or alternatively you may choose Import data from the File menu). The Dataset Importer dialog will appear. An example of the Dataset Importer dialog with some data files already selected is shown in Figure 4.
b. On the Dataset Importer dialog, set the Dataset Type pull down menu to the type of data you wish to import. Currently, the following types of data can be imported into EmisView:
· NIF3 ASCII Nonpoint Inventory (ASCII format only)
· NIF3 ASCII Point Inventory (ASCII format only)
· IDA Nonpoint/Nonroad Inventory
· IDA Point Inventory
· IDA Onroad Inventory
·
ORL
· ORL Nonroad Inventory
·
ORL
· ORL Point Inventory
Note that the fastest
type of file to import is an IDA Nonpoint/Nonroad Inventory; the next fastest
is a NIF3
Figure 4. Dataset Importer Dialog

c. If you are importing data from one or more files, be sure that the From: File radio button is selected. Next, click the Browse button to select the files to import. If you are importing a NIF3 dataset (ASCII is the only format currently supported) you will need to select multiple files.
i. You may select multiple consecutive files in the file browser by clicking on the first file, then holding the shift key down and clicking on the last file to select a set of consecutive file names.
ii. To select nonconsecutive file names, hold the control key down and click on individual files. First time users should choose the following files in the emisview\data\nif3\area_nonpoint directory: ky_np_ce.txt, ky_np_em.txt, ky_np_ep.txt, ky_np_pe.txt.
iii. Once you are done selecting all the files to import, click Select.
iv. If you have not selected all the files needed for your chosen Dataset Type. EmisView will notify you and you will need to select your files again.
v. When you return to the dataset dialog, one or more tables should be listed in the tables section and their names are based on the names of the files you selected. For first time users, the Importer dialog should now look like the one shown in Figure 2. Note that an additional Emission Summary table is created for NIF3 and ORL dataset types. This will be generated automatically by EmisView.
d. If the data are already loaded in the emissions data database (e.g., you are a CONCEPT user or you had previously imported the data files) and you are importing NIF3 files, select the Database radio button and make sure the table names match the ones in your database. If they do not match, you may edit the table names by double clicking in the Name column for the tables to create.
e. On the Dataset Importer dialog, specify the Country for which you are importing data.
f. In the Tables section, if you are unhappy with the names chosen for the tables and would like to add a prefix to all the table names (e.g., to add a state abbreviation to NIF3 table names), enter a prefix in the “Add Prefix to Table Names” field and then click the Update button. Alternatively you may double click in the field containing an individual table name and edit it manually.
g. If you would like any existing tables in the database to be overwritten if tables with the same names already exist in the database, check the “Overwrite the tables if they exist?” checkbox.
h. NOTE: Importing data files can take a long time (2-20 minutes for a single state) and can make your computer very slow to access in the meantime. Once you are ready to proceed with the import, click the Import button at the bottom of the Dataset Importer dialog. If you do not wish to continue at this time, click the Cancel button.
i. Once the import process has completed, a Dataset Properties Editor window (see Figure 5) will appear from which you may specify the properties / metadata for the dataset.
- Specifying properties of a dataset: After the
import process has completed, or after the Configure
button is clicked from the Datasets tab, a Dataset
Properties Editor window similar to the one shown in Figure 5 appears that
shows the properties of (i.e., metadata for) the dataset. Note that as
many properties as possible are filled in automatically during the import
process.
Figure 5. Initial Dataset Properties Editor
Window

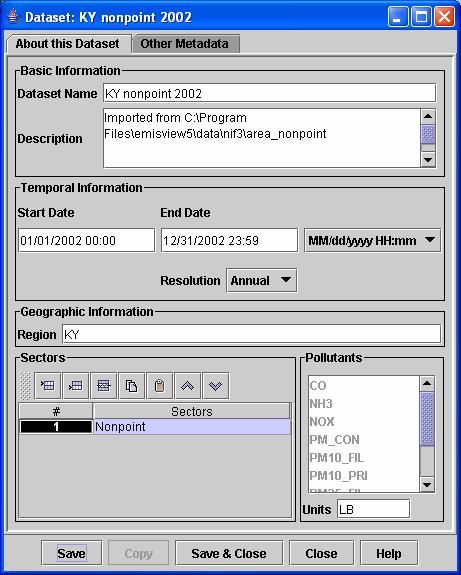
a. On the About this Dataset tab, you must specify a unique Dataset Name. If you are a first-time user and wish to follow on with the steps as a tutorial, please name the dataset KY nonpoint 2002.
b. You may specify or expand on the Description of the dataset.
c. If the temporal information—the start and end dates and resolution—were not filled in properly by the importer, you may adjust this information. The available resolutions are Annual, Monthly, Weekly, Daily, and Hourly. Note that the temporal information is assumed to be consistent throughout the dataset. For NIF3 files, the temporal information is obtained from the first record of the emissions table, but all records are assumed to be for the same time period. To address this, you may wish to separate out records with different time periods and import these as separate datasets to provide accurate comparisons between emissions values.
d. If the geographic information, which currently consists of the Region, was not filled in appropriately by the importer, you may adjust this information (e.g., you may wish to change “US” to the state to which the inventory applies). Enter KY for the KY nonpoint 2002 dataset.
e. Specify a sector for the first time by double clicking on the “Double click to select” in the sectors list and choosing a sector from the pull-down menu (e.g., Nonpoint). If an additional sector applies, click the icon second from the left on the Sectors toolbar to add another row and specify the second sector as you did the first. If you wish to change any of the assigned sectors, double click on the name of the sector and a pull-down menu will appear from which you can choose a new sector. If you are unsure what any of the buttons in the toolbar in the Sectors list are for, hold your mouse over a button and a tool-tip will appear with information about the button.
f. The Pollutants section shows a list of the pollutants that were read in for the Dataset. You cannot edit this, but you may scroll through the list to examine its values.
g. If the Units are not properly specified for the dataset, backspace over the specified units and fill in the proper units. Note: Some NIF3 files have data with multiple units in the same file. Currently, EmisView does not support a single Dataset having multiple units. Thus, when you import a NIF3 file with mixed units, EmisView will create an emissions (EM) file with any entries that have units different from the units on the first line of the file and place it in the directory that contained the original dataset. This file will be named original_em_file_name.reimport.txt. You may reimport this file into another dataset at a later date. Eventually, units conversions may be added to EmisView to address this situation.
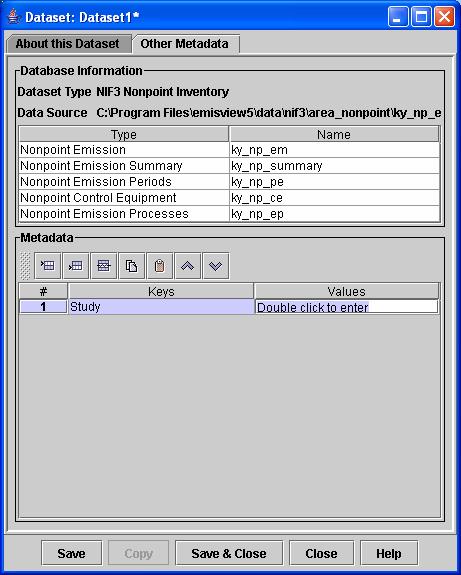
h. To see and specify other properties of the dataset, click on the Other Metadata tab. The dataset type, data source, and data tables are filled in by EmisView during the import process. The Metadata section allows you to specify other metadata values using keyword-value pairs (e.g.,Keyword=”Study”, Value=”SIP 2007”). Eventually, searching on these keywords and values will be supported.
Figure 6. Other Metadata tab Dataset
Properties Editor Window
i. When you are finished editing the properties of the dataset, click Save or type Control-S. The Dataset Properties Editor for the KY nonpoint 2002 dataset should now look like Figure 7. You should see your dataset with its updated values in the table on the Datasets tab. To close the window click Close or Control-L. Alternatively, you may use the Save & Close button (Control-Shift-S) to both Save and Close the Dataset Properties Editor window.
j. If you wish to exit without saving, click Close and then select No in the confirmation dialog when asked if you wish to save your changes. To cancel the close operation and return to the Dataset Properties Editor window, click the Cancel button on the confirmation dialog.
k. Note that in the current version of EmisView, you must run an Analysis to view the data in your imported dataset. The steps in this guide will lead you through this process. In future versions, there may be a “quick view” feature that will allow you to see the data without running an Analysis.
Figure 7. Filled in Dataset Properties
Editor Window
- If you are a first-time user and you wish to follow along with the
tutorial example, follow these steps to import an IDA Nonpoint/Nonroad
dataset after you have finished importing the
a.
Click New on the Datasets tab.
b. On
the Dataset Importer dialog, choose IDA Nonpoint/Nonroad Inventory for the Dataset
Type.
c. Click
the Browse
button and then choose the following files in the First-time users should import the file emisview\data\ida\arinv.stationary.nei96_NC.ida.txt
then click the Select button.
d. Click
the Import
button. Note that it may take a couple of minutes to import the data.
e. In
the Dataset Properties Editor window, set the Dataset Name to NC IDA area 1996, set the Region to NC, and double click on
the list of Sectors and choose Nonpoint
as the sector.
f.
Click
Save & Close. You should see the new Dataset listed in the
table on the Datasets tab of the Main GUI, similar to that shown in Figure
8.
The next few bullets discuss other
features of the Datasets tab, but a tutorial is not given for those
features. Feel free to experiment with them
on your own.
Figure 8. Datasets Tab with Datasets Loaded
- Buttons on the Datasets Tab: On the Datasets tab (see
Figure 8), below the table there are buttons that allow you to perform
actions related to Datasets. You can perform the following actions with
the buttons:
a. To create a new dataset, click the New button and follow the instructions in the Importing Data into EmisView step. The data will be imported from one or more files and loaded into tables in the emissions database, or for CONCEPT users the new dataset will refer to data that are already in the database.
b. To edit or view the properties associated with datasets, select the datasets of interest by checking the corresponding checkboxes in the Select column, then click the Configure button. One dataset editor will appear for each selected dataset. Follow the instructions in the Specifying properties for a dataset section to edit or view the properties of the datasets.
c. To rename multiple datasets, select the datasets you wish to rename and click the Rename button, then follow the instructions given in Renaming Multiple Datasets.
d. To delete multiple datasets, select the checkboxes corresponding to datasets you wish to delete and click the Delete button. Note that currently, the underlying data tables in the emissions database will not be deleted, only the properties that correspond to the dataset.
e. To get Help on the Datasets tab, click the Help button.
f. Note: the Copy button is disabled on the Datasets tab (but is enabled on the other tabs) because we do not support copying of the corresponding emissions data.
- Viewing and configuring properties for datasets: Note that you
can show and edit the properties for more than one Dataset at a time.
a. On the Datasets tab, some properties are shown in the table, but you cannot edit them here.
b. Check the boxes in the Select column for the datasets for which you wish to view or edit the metadata.
c. Click Configure to open the Dataset Properties Editor window for each selected dataset.
d. Edit the properties for the dataset as described in Specifying properties of a dataset. Note that you may rename a single dataset from this window by changing the entry in the Dataset Name text field.
- Renaming Multiple Datasets: You can rename multiple datasets
during the same operation.
a. On the Datasets tab, check the boxes in the Select column for the datasets that you wish to rename.
b. Click Rename to open the Rename dialog.
c. If you wish to add a prefix to all of the dataset names, enter the new prefix in the Prefix text field, then click Update Names.
d. If you wish to add a suffix to all of the dataset names, enter the new suffix in the Suffix text field then click Update Names. Note that if you still have an entry in the Prefix field and have already clicked Update Names, you should delete the entry from the Prefix text field prior to clicking Update Names a second time.
e. To manually change a name, double click on the name in the right-hand column and edit the name.
f. When you are finished specifying the new names, click OK to accept the changes, or Cancel to leave the original names intact.
- Overview of the Datasets Table: On
the Datasets tab, there is a table that shows some properties of the
loaded datasets. Note that you
cannot edit the properties directly from the table but instead you must
edit them as described above.
a. There are buttons on the toolbar above the table. These buttons allow you to perform operations that control the appearance of the table. From left to right, the buttons on the toolbar are:
·
multicolumn sort
![]() ,
,
·
filter rows ![]() ,
,
·
show/hide
columns ![]() ,
,
·
format columns ![]() ,
,
·
reset
the table to its default state ![]() ,
,
·
select
all entries in the table ![]() , and
, and
·
clear the
selection of all entries in the table ![]() .
.
b. The sort, filter, and show/hide functions are described further below.
c. If you wish to change the width of any of the columns in the table, place your cursor on the table header on the line that separates two columns and then click and drag the separator to change the column width.
d. To rearrange columns in the table, place your cursor over the header for the column you wish to move, and click and drag the column to its new location.
- Sorting the Datasets table based on one or
more columns:
a.
On the Datasets tab,
for a single column sort, click on the header of the table column that you wish
to sort by (e.g., Type). Click the column header again to toggle the sort
between largest to smallest and smallest to largest.
b.
To sort the table based on the values of multiple
columns, click on the sort icon ![]() on the toolbar to bring up the sort dialog.
Choose the first column to sort by
and whether it should be Ascending or Case Sensitive. To add another column to sort by, click the Add button and specify the column and
other parameters for the second column.
Continue until you have added all desired columns for your sort, then
click OK.
on the toolbar to bring up the sort dialog.
Choose the first column to sort by
and whether it should be Ascending or Case Sensitive. To add another column to sort by, click the Add button and specify the column and
other parameters for the second column.
Continue until you have added all desired columns for your sort, then
click OK.
- Filtering the entries on the Datasets table: You can show
only those datasets that have certain attributes by specifying those
attributes as part of filter criteria.
a.
On the Datasets tab,
click the filter icon ![]() to bring up the
Filter Rows dialog.
to bring up the
Filter Rows dialog.
b.
Click Add Criteria to add a filter criterion.
c. Click on the first row under the column name heading and select the column you wish to use for the criterion (e.g., “Name” for first-time users).
d. Click on the operation field to choose the operation (e.g., “starts with” for first-time users).
e. Click on the value field to specify a value for the criterion (e.g., “KY”), then hit return to accept the entry.
f. If you wish to add another criterion, click Add Criteria again and specify the column name, operation, and value for the second criterion.
g. Select whether to show matches that meet ALL criteria or ANY criteria.
h. When you are finished specifying the criteria, click OK to apply the filter, or Cancel to cancel the operation.
i.
To remove the filter (and any sort that is applied), click the Reset icon ![]() .
.
- Showing and hiding the columns in the Datasets table: You can
control which of the available columns of information about datasets are
visible in the table.
a.
On the Datasets tab, click
the show/hide columns icon ![]() to bring up the Show/Hide Columns dialog.
to bring up the Show/Hide Columns dialog.
b. You may drag your mouse over the column names to select them and then click Hide or Show to change the state of the Show? column. Alternatively, you may click a checkbox in the Show? column manually to change its state.
c. Click OK once you have made your adjustments, or cancel to leave the columns as they were.
d.
To again show all the columns, click
the Reset icon ![]() .
.
4. Subsets
Subsets in EmisView allow you to create a subset of the data in your dataset, and also to aggregate the data according to its attributes (e.g., by county or SCC). In the subset, you can specify a region to include, a set of SCC codes, a set of columns to include, and a filter to apply to the rows. You may also specify how to aggregate or report the data (e.g., sum by county or SCC). As shown in Figure 1, when an EmisView Analysis is run, a Subset is used in conjunction with a Dataset and the resulting data is passed to the Product for display. The functions available on the Subsets tab are very similar to those available from the Datasets tab. These include the buttons on the toolbar above the table of Subsets, and the buttons New, Copy, Rename, Delete, Configure, and Help. See the appropriate sections of the Datasets tab discussion for descriptions of the functions that are common between the Datasets and Subsets tabs.
The Copy button is new on the Subsets tab, as copying is supported for Subsets but not for Datasets. The Copy dialog is very similar to the Rename dialog described above. Using the Copy function will create copies of each of the subsets instead of just changing the names of existing subsets.
- The “All Records” Subset:
EmisView comes prepopulated with a subset named “All Records”. This
subset will pass through all of the emissions records to the Product
without making any changes to the emissions data records. Note that for
some types of data (i.e., NIF3 and ORL), a summary table is created during
the import process, and it will be the contents of this summary that are
shown to the user when the “All Records” subset is applied.
- Creating a new Subset:
a. On the Subsets tab, click New. The Subset Editor window will appear, similar to the one shown in Figure 9.
Figure 9. Subset Editor Window
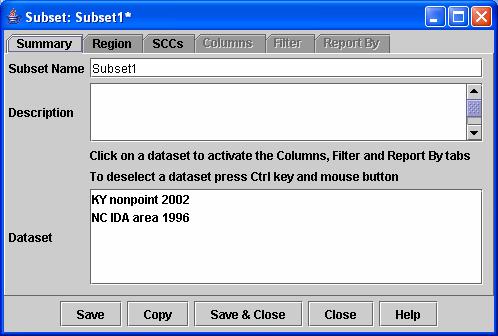
b. On the Summary tab of the Subset Editor window enter a unique Subset Name (first time users should set the Subset Name to Example). In general, the name should be descriptive according to what the subset will do (e.g., Sum by SCC, or Select Counties A and B). Note: The simplest Subset is one that will pass through all of your data to the analysis Product. As noted in item 1, one of these subsets has already been created for you, called “All Records”. If you desired to create such a subset yourself, you would click Save without clicking on a dataset or changing any of the settings available from the other tabs.
c. Fill in a Description for the Subset that describes its purpose and function. Note that you can come back and fill this in with more detail after you more fully specify the subset. First-time users should set the Description to “Illustrates how to use a Subset”.
d. If you are not creating a “pass-through” subset, choose a Dataset from which the subset will obtain the preferred dataset type and a list of available columns. Note that you can later apply the subset to any Dataset that possesses the columns that are referenced by the subset. First-time users should select the KY nonpoint 2002 dataset, and then click Save—but leave the window up so you can make adjustments as we run through all the features of the Subset.
- First-time users: Create
an analysis to illustrate the use of subsets. Before moving on to explore the features
of the Subset, it is recommended that you create an Analysis so you can
see how the analysis results change as you adjust your subset.
a. To create an Analysis, go to the Analyses tab and click New. An Analysis Editor window will appear similar to the one shown in Figure 10.
b. Set the Analysis Name to: KY nonpoint 2002.
c. Set the Description to “An example Analysis”.
d. Click on All Records as the Subset, and choose KY nonpoint 2002 as the dataset. The Table and Plots Product should be automatically selected. At this point the selections for Subset, Dataset, and Products should look like the ones in Figure 10.
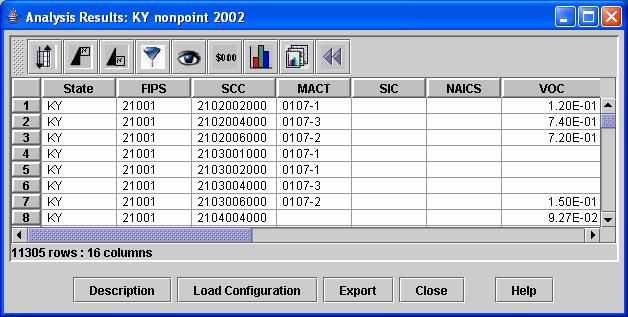
e. Next click Run. This will cause an Analysis Results window similar to the one in Figure 11 to appear that shows all of the sources in the KY nonpoint 2002 dataset. Note the number of rows that are shown (in the lower left corner of the analysis results table). For the KY nonpoint 2002 dataset, there should be 11305 rows and 16 columns. (The unfamiliar buttons on the tool bar in the Analysis Results window will be explained in Section 6.)
f. Next, in the Analysis Editor window, select Example as the subset and type Control-S to save the Analysis. Leave the Analysis editor window up and click Run to rerun the analysis. The first time you run using the Example Subset, it should produce the same results as were obtained using the All Records Subset with 11305 rows. Once you verify this, you may Close the new Analysis Results window.
g. As you go through the rest of this section, it is suggested that you leave the Analysis Editor and some of theAnalysis Results windows up as the features of the Subset Editor window are illustrated. By rerunning the Analysis, you will be able to see how the analysis results change as you change the Subset.
Figure 10. Analysis Editor Window
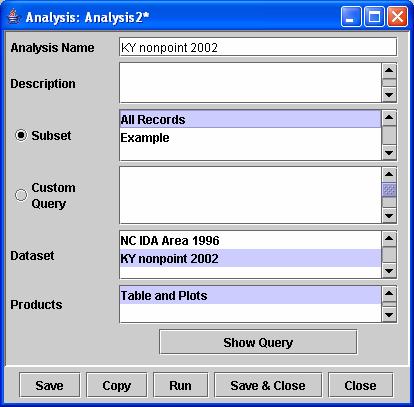
Figure 11. Analysis Results Window
- Specifying a Region for the Subset: The Region tab (Figure 12) of the Subset Editor window allows you to create an analysis on a particular geographic (sub)region of your data. If you do not wish to subset your data based on the region, leave the Region Filter to Apply set to Entire Region.
a.
If you are a first-time user, go to the Subset Editor window for the Example subset, if
it is still open. If the window has been
closed, go to the Subsets tab, select the checkbox next to the subset named
Example, and click Configure.
b. If you wish to select a region based on one or more countries and/or states, set the Region Filter To Apply to Country & State. Then you can select one or more countries to include and one or more states. When you run your analysis, only data associated with the selected countries and states will be included.
c.
For first-time users:
To see what happens when you apply a Country & State subset to the KY nonpoint 2002 dataset:
i.
Click the “clear all”
button ![]() on the toolbar above
the State column.
on the toolbar above
the State column.
ii.
Click on the Select
checkbox next to some state other than
iii.
Type Control-S to save the subset.
iv.
Now go to the KY nonpoint 2002 Analysis Editor window (be sure that the Example subset
is selected) and then click Run.
v.
The Analysis Results
window should be empty because your selected Dataset included data only for
vi.
Press the Close button on the Analysis Results
window.
Figure 12. Region tab of the Subset Editor
Window (Country & State Option)
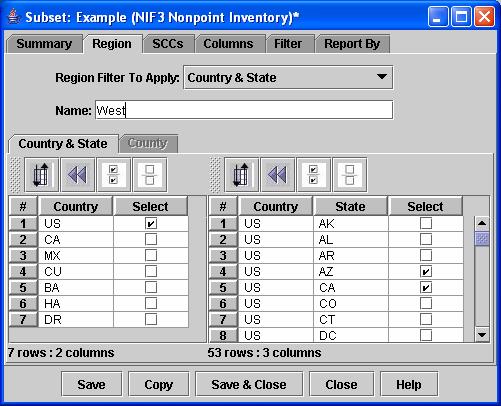
d. You may wish to give a name to the region that you have selected by filling in a value for the Name on the Region tab. Eventually, EmisView may save the regions you have specified for later re-use.
e. To select a region based on counties and/or
their attributes (e.g., nonattainment status, or county name):
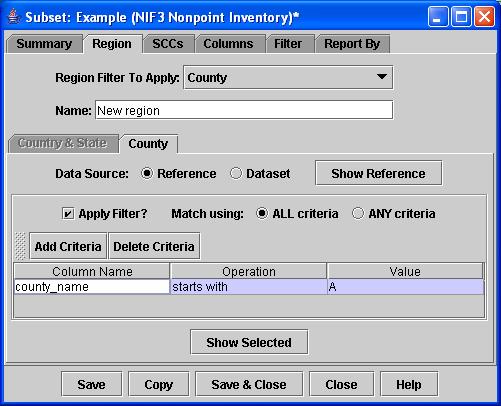
i. From the Subset Editor window, set the “Region Filter To Apply” to County.
ii. If you wish to see the reference information that is available for counties, click the Show Reference button. The county reference has a number of fields, including state-county FIPS code, state abbreviation, time zone, center latitude and longitude, the bounding latitudes and longitudes (north, south, east, and west), and information about nonattainment status.
iii. Go back to the County tab of the Subset Editor window. To specify filter criteria based on the attributes of the counties, click the Add Criteria button to add a criterion.
iv.
Choose the Column Name for
the criterion by clicking on the first row under Column Name in the
table (first-time users should select “
v. Next, click on the Operation for the criterion (first-time users should select “starts with”).
vi. Now specify the value for the criterion (first-time users should enter “A”). Be sure to hit the return key after entering the A. The Subset Editor should now look like the one in Figure 13.
Figure 13. Region tab of the Subset Editor
Window (
vii. To see which counties in the reference database match your criteria, click Show Selected. First-time users will see all of the counties in the reference database that start with A.
viii. To show the counties in your selected dataset that match the criteria, set the Data Source (just below the County tab name) to Dataset and then click Show Selected (note that this operation can be slow to execute on some computers).
ix. To show all counties that exist in your dataset, uncheck the Apply Filter? button and then click Show Selected (be sure the Data Source is still Dataset).
x. Check the Apply Filter? button so the region filter is activated for the subset, then type Control-S.
xi. First-time users, go to the KY nonpoint 2002 Analysis Editor window and click Run. You should see 295 rows (those that correspond to the counties whose names start with A). Press the Close button to close the new Analysis Results window.
f. To deactivate a state-based or county-based filter, set the “Region Filter To Apply” to Entire Region.
i. Type Control-S to save the subset.
ii. First-time users, go to the KY nonpoint 2002 Analysis Editor window and click Run. You should see all 11305 rows again because the region filter has been deactivated.
iii. Press the Close button to close the new Analysis Results window.
- Specifying SCCs for the Subset: The SCCs tab of the
Subset Editor window allows you to select only the data rows that match
the desired SCCs. The SCCs tab of the Subset Editor window is shown in
Figure 14.
a. To specify filter criteria based on SCCs, click the Add Criteria button to add a criterion.
b. Next choose the Column Name and Operation by double clicking on the fields in the table.
c. Specify the Value. Note: The values are case sensitive.
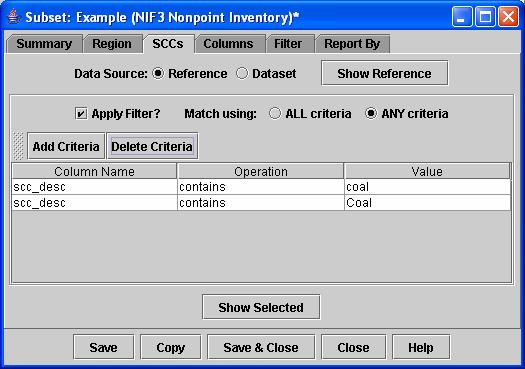
d. First-time users: Specify the criterion “scc_desc contains coal” as shown for the first criterion in Figure 14.
e. To see which SCCs in the reference database match your criteria, click Show Selected while the Data Source: Reference radio button is selected. First-time users will see some SCCs that contained the phrase “coal”. Note that the results are a little unexpected in that SCCs that contain the word Charcoal appeared, but other expected Coal-related SCCs did not.
f. To specify another criterion, click Add Criteria again and specify the Column Name, Operation, and Value second criteria. First-time users: Specify the criterion “scc_desc contains Coal
g. When you have multiple criteria, you must decide whether you wish to require your data rows to match all the criteria or any of the criteria. Select the appropriate button: ALL criteria or ANY criteria. (First-time users: Select ANY criteria). ”. Now your Subset Editor should look like the one in Figure 14. Click Show Selected to see the SCCs in the reference database that match any of the criteria. First-time users will see that many more SCCs are now included in the list.
Figure 14. SCCs Tab of the Subset Editor
Window
h. To show the SCCs in your selected Dataset that match the criteria, set the Data Source to Dataset and then click Show Selected. First-time users should see four rows.
i. First-time users: To see the impact of the SCC filter on your results, type Control-S to save the subset, then go to the KY nonpoint 2002 Analysis Editor window and click Run. You should see 442 rows, which are the records with SCC codes that meet the specified criteria.
j. To turn the SCC filter off in the subset, uncheck the Apply Filter? button. Thus, to show all SCCs that exist in your Dataset, click Show Selected (the Data Source should still be Dataset for this to work properly). First-time users should see 114 rows, which are all of the SCCs in the Dataset.
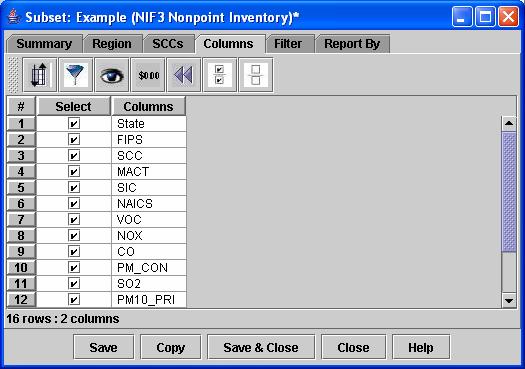
- Specifying Columns for the Subset: You can use the Columns tab of the Subset Editor window to choose the columns
that will appear in the data passed to the Product. Note that the Columns
tab will be activated only if you have a dataset selected on the Summary
tab of the Subset Editor window. To specify the columns that appear in the
analysis results:
a.
Go to the Columns tab of the Subset Editor.
The columns that exist in the dataset you selected on the Summary tab will appear on the Columns tab, as shown in Figure 15.
b. Uncheck any columns that you are not interested in seeing in your analysis.
c. Type Control-S to save.
d. First-time users; to see the impact of the Columns tab setting on the analysis results, go to the KY nonpoint 2002 Analysis Editor window and click Run. Only the columns that still remain checked should appear in the results.
e.
To again show all the columns
in your analysis results, click the “select all” button ![]() on the toolbar.
on the toolbar.
Figure 15. Columns Tab of the Subset Editor
Window
- Specifying a Filter for the rows
produced by the Subset: Using the Filter tab of the
Subset Editor, you may specify a filter based on the attributes of the
records in the dataset.
a.
Go to the Filter tab of the Subset Editor window.
b. To add a criterion for the filter, click the Add Criteria button.
c. Specify the Column Name, Operation, and Value for the Criteria by clicking on the entries for the criterion (first-time users should specify NAICS > 0 to show all rows with nonempty NAICS codes).
d. To see the impact of the Filter tab setting on the analysis results, first-time users should go to the KY nonpoint 2002 Analysis Editor window and click Run. You should see 5060 rows in the result (assuming you have the Region set to Entire Region and the Apply Filter? button on the SCC tab is unchecked; otherwise the number of rows will be different).
e. You may add another criterion by again clicking the Add Criteria button. First-time users should enter the criteria VOC > 400 to show rows for which VOC is greater than 400.
f. Based on your goal, select the appropriate button for Match using: ALL criteria or ANY criteria. (First-time users: Select ALL criteria). Now the Subset Editor window for first time users should look the one in Figure 16.
Figure 16. Filter Tab of the Subset Editor
Window

g. To see the impact of the additional criterion on the analysis results, first-time users should type Control-S, go to the KY nonpoint 2002 Analysis Editor window, and click Run. You should see 14 rows in the result (assuming you have the Region set to Entire Region and the Apply Filter? button on the SCC tab is unchecked; otherwise the number of rows will be different).
h. If you need to delete a criterion, click on that row in the table to select it and then click Delete Criteria.
i. To turn off the general Filter for the records, uncheck the Apply Filter? button.
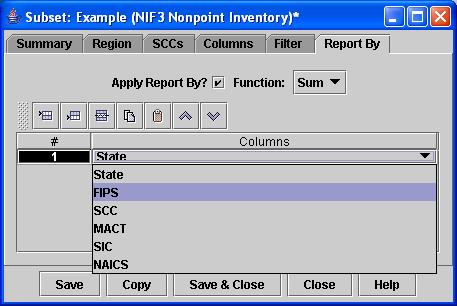
- Specifying Aggregation for the
Subset: You may
specify aggregation for the subset using the Report By tab of the Subset
Editor window (Figure 17). When you
add items to Report By, the values in the numeric columns (including the
emissions) will be aggregated for each unique combination of values in the
columns you chose to report by (e.g., show the sum for each county, or
each unique combination of NAICS and SCC code).
a. To add a field to Report By, click the leftmost button on the toolbar to insert a row in the table.
b. A pull-down menu will appear from which you can choose a descriptive column to retain in the result of your analysis. The list of descriptive columns is specified according to the type of dataset that you have selected for your analysis. First-time users should select FIPS. Note that when you save a Subset that uses the Report By feature, you may get a message about some columns being deselected. This is necessary so that the nonnumeric data in fields listed on the Report By tab will not be shown in the result when it doesn’t make sense to show them (e.g., if you chose to Sum by SCC, it is not possible to show a value for the NAICS code because it does not make sense to sum the NAICS)
Figure 17. The Report By tab of the Subset
Editor
c. To see the impact of the Report By tab on the analysis results, first-time users should type Control-S, go to the KY nonpoint 2002 Analysis Editor window, and click Run. You should see 120 rows in the result (assuming you have the Region set to Entire Region and the Apply Filter buttons on the SCC and Filter tabs are unchecked; otherwise the number of rows will be different).
d.
You may add additional fields to report by
as needed. For example, to see a report by FIPS and MACT, click the first button on the toolbar to add a second row, and
then choose MACT as the second column to Report By. NOTE: To see the MACT codes in the
analysis results, you must go back to the Columns tab and recheck the MACT
column to make sure it will be shown.
e. To see the impact of the second item on the Report By tab, first-time users should type Control-S, go to the KY nonpoint 2002 Analysis Editor window, and click Run. You should see 1400 rows in the result.
f.
The buttons on the toolbar for this window are
as follows (from left to right):
insert row above current line, insert row below current line, delete row, copy
row, paste in to the selected row, move the selected row up, move the selected
row down.
g. If you need to delete a column to report by, click on that row in the table to select it and then click the third button in the toolbar to delete the selected column.
5. Analyses
Note: Contrary to the order of the tabs in the Main GUI, Analyses are discussed before Products because the default Product (Table and Plots) is sufficient for many Analyses.
In EmisView, Analyses are used to tie together the Datasets, Subsets, and Products to create meaningful Analysis Results such as tables and plots. Analyses are created from the Analyses tab of the Main GUI. The functions available on the Analyses tab are very similar to those available on the other tabs. These include the buttons on the toolbar above the table of Analyses, and the buttons New, Copy, Rename, Delete, Configure, and Help. See the appropriate section on the Datasets tab for descriptions of the functions that are common between the tabs. The Analysis Editor window (see example in Figure 18) is used to select the Subset, Dataset, and Product to use for the Analysis. In the Analysis Editor window:
- The Analysis Name is specified at the top of the Analysis, followed by a Description of the Analysis. It is a good practice to always fill in a description for the Analysis to help you remember the purpose of each Analysis the next time you open it.
- Next, you should select a Subset. This will cause EmisView to list only the Datasets that can be used with that Subset. EmisView determines this matching by examining the columns that are referenced by the Subset and finding the Datasets that possess those columns.
- After selecting a Subset, you should then select a Dataset to use for the Analysis.
- Finally, select a Product(s) that will display the results of your Analysis.
Now that you
have fully defined your Analysis, you can click Save to store the configuration of the Analysis and then click the Run button to perform the
Analysis. When you click Run, EmisView
follows the flow show in Figure 1: it generates a query that uses the data from
the selected Dataset, aggregates and subselects the data as specified by the
Subset, and then shows the results of the query using the selected analysis
Product. Currently, results are typically shown using the Analysis Engine
table, slightly modified for EmisView. Please see the section on Analysis Results for more information on the Analysis
Engine table. If a custom product was defined, some plots may also be generated
(see the section on Products and Analysis Results for more information on
custom Products).
Figure 18. The Analysis Editor Window
Some of the features of the Analysis Editor window are as follows:
- The Show Query button shows the SQL query that will be issued to the database when the analysis is run. This can be helpful to those familiar with SQL; for example, the SQL query can be examined if the analysis results do not have the form expected. First-time users, go to the KY nonpoint 2002 Analysis Editor window and click Show Query to see the query that will be used when the Analysis is run. Close this window when you are done.
- By selecting the Custom Query button, a sophisticated user of SQL can enter a query directly. This query will then be stored with the Analysis. Note that the selection of a dataset is irrelevant when this feature is used, as the tables to use are referenced directly in the query. Also note that if an invalid query is entered, EmisView has no features for determining what is wrong with the query.
- First-time users, go to the KY nonpoint 2002 Analysis Editor window and select Custom Query.
- In the text box, enter the query “select * from ky_np_pe” (without the quotes). This will show the entries in the PE table that correspond to the KY nonpoint 2002 dataset. Note that you have to reference the table name (i.e., ky_np_pe) directly.
- If you want to find out the names of the tables used for the datasets so you can access them in a custom query:
- Go to the Datasets tab in the Main GUI.
- Check the select button for the Dataset of interest.
- Press the Configure button.
- Go to the Other Metadata tab in the Dataset Properties Editor window.
- Look at the names of the tables under the Name column in the Database Information section.
6. Analysis Results
The Analysis Results window appears after you run your analysis. The examples given here were created using the default Product that is provided automatically with EmisView ‑ the Table and Plots. This product uses a slightly adapted version of the Analysis Engine to display the results of the Analysis. Eventually, there will be other types of products (e.g. dataset comparisons and maps) that may come up in different type of Analysis Results windows. An example of the Analysis Results window is shown in Figure 19. The name of the window is “Analysis Results: Analysis Name”. The table in this window works similarly to the tables on the EmisView Datasets, Subsets, Analyses, and Products tabs in that you can sort a column by clicking on the header, and use the items in the toolbar to define a multicolumn sort, filter rows, show/hide columns, and format columns.
Figure 19. Analysis Results as a Table
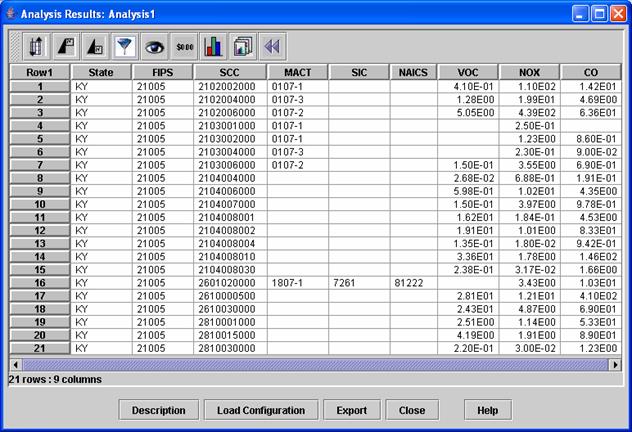
Note that while you can filter rows and show/hide columns using the buttons on the toolbar of this window, when using EmisView it is preferable to perform those particular functions as part of the Subset. This is because when filtering of columns and rows is done using Subsets, the specifications can be re-used more readily in other analyses.
If you are not happy with the precision or form of the numbers that are shown in the table, you may modify the settings in the user_preferences.txt file:
· NUMBER_OPTION allows you to choose between Standard_Notation and Scientific_Notation
· format.double.significant_digits allows you to specify the number of significant digits of data to show (e.g. 3 significant digits would result in numbers like 123000, or 2.14)
· format.double.decimal_places allows you to control the default number of decimal places shown for the numbers in the table.
The buttons below the table provide some useful operations. The Description button provides a read-only information page that specifies the Analysis, its description, and the query that was used to create the Analysis Results. The Load Configuration button allows you to load an Analysis Configuration containing sort, filter, format, and plot configurations for the table (analysis configurations are described in more detail below). The Export button allows you to export your data to .csv or other types of delimited ASCII formats that can then be loaded into a spreadsheet or other software for further analysis. The Close button closes the window, and the Help button brings up on-line help for the analysis engine table.
In the Analysis Results table, some icons were available on the toolbars found on the EmisView GUI, but the following buttons are new:
- Show
Largest N rows

- Show
Smallest N rows

- Create
Plot

- Show
Analysis Configuration

These functions are useful when dealing with numeric data such as emissions data. The Show Largest N rows icon brings up a dialog that allows you to choose a data column and to specify a number of rows to show or a percent of rows to show. The table will then show only the specified number of rows with the largest values in that column. The Show Smallest N rows icon works in the same way but instead shows the smallest rows. You may also choose these functions from a pop-up menu that comes up when your right mouse button is clicked. In that case, the column is selected automatically according to the position of your cursor when the menu is brought up.
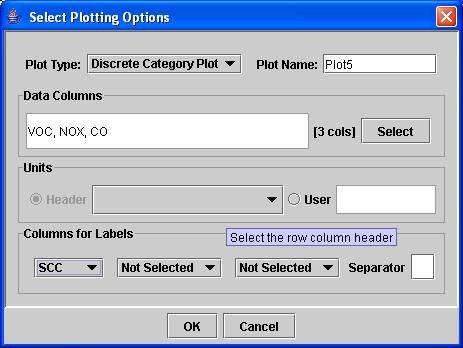
To create a plot, click the Create Plot icon. This causes the Plotting Options dialog to appear (Figure 20). From here you can specify the Plot Type, the Plot Name to use in the Analysis Configuration, the Data Columns to pass to your plot (by pressing the Select button will bring up a column selection dialog), the Units to specify, and the column(s) to use to label the entries on the plot (e.g., SCC, FIPS, or state). If you wish to use multiple columns for labels, you may specify a separator to go between the labels (e.g., ‘-‘, or ‘,’). The Header option for units is greyed out because there no units header row is produced by EmisView. When you load in other files that specify units for each column (e.g., outputs from Smkreport), the Header option is available.
Figure 20. Plotting Options Dialog
Once you click OK on the Plotting Options dialog, the Customizing Plot dialog for the selected type of plot will appear. An example of this dialog for a Discrete Category Plot is shown in Figure 21. Each Customize Plot dialog lists the options available for the plot. To change one of the options, click the corresponding Edit button. The details of the editors that appear when Edit is clicked (e.g., choosing the title text and the font size and color to use) are described in the MIMS Analysis Engine documentation, which is included with the EmisView on-line help.
Figure 21. Customizing Plot Dialog

To specify or change the order of the data variables shown on the plot, click the Set button in the Data sets section of the Customize Plot dialog. (Note that the term “data set” here does not correspond to an EmisView Dataset; instead, it is more like a data variable to use on the plot. Eventually, the terminology on this window may be changed to make this clearer.) When the Set button is clicked, the Analysis Engine Data Set Selector appears (Figure 22). If you wish to use all of the variables in the order in which they are shown, just click OK. If instead you wish to specify the order of the variables, double click on the variable names in the Available Data Sets area in the order that you want them to appear. To remove an entry from the Selected Data Sets list, double click on it, or single click and press the Remove button. Once you have selected all the datasets you want to plot, click OK to return to the Customizing plot dialog. Then you can click the View Plot button in the Customize Plot dialog to see the plot. On Windows, the plot will appear in Adobe Acrobat. On Linux, it will appear as an image in its own window. Figure 23 is an example of a discrete category plot.
If you wish to save the plot in a particular image format, you may click the Browse button in the Page Options section of the Customize Plot dialog and choose a file name. Note that the “Files of type” pull-down menu on the file browser shows the formats that can be saved; the supported formats are Postscript (.ps), JPEG (.jpg), LATEX (.ptx), PDF (.pdf), and Portable Network Graphics (.png). Alternatively, you may enter the file name with an appropriate extension in the text field in the Page Options section of the dialog. Once you have chosen or entered the file name, click the Save button next to Browse and the plot will be saved to the specified location and format.
Figure 22. Analysis Engine Data Set
Selector
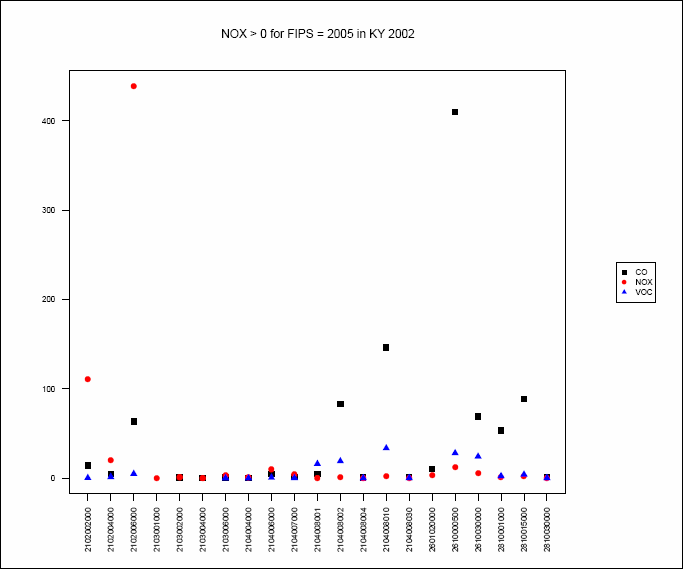
Figure 23. An Example Discrete Category
Plot
Once you have created a plot, information about it is stored
by the Analysis Engine as part of the Analysis Configuration. To see the contents of the Analysis
Configuration, which include the list of stored plots and information about
sort, filter, and format settings that have been applied to the table, click on
the Analysis Configuration icon ![]() . A
dialog similar to the one shown in Figure 22 will appear. To view a plot, click
on the row corresponding to the plot in the table and then click the View button. To customize the settings for the plot, click
the Edit button. To remove the plot from the list of stored
plots, click the Delete button. If you
wish to save an analysis configuration for
future use, you can specify a file name using the Browse button or by entering a directory and file name into the Save As field (see Figure 24). It is
recommended that you give these configuration files a “.cfg” extension so you
can recognize them later. Only the elements of the Analysis Configuration for
which the Save? checkbox is activated will be saved. If you highlight multiple rows and click the Select button, the Save? checkbox for those rows will be activated. Alternatively, if you highlight multiple rows
and click the Clear button, the Save? checkbox will be turned off. Once
you have saved an analysis configuration, you can use it later in EmisView to
create a custom Product.
. A
dialog similar to the one shown in Figure 22 will appear. To view a plot, click
on the row corresponding to the plot in the table and then click the View button. To customize the settings for the plot, click
the Edit button. To remove the plot from the list of stored
plots, click the Delete button. If you
wish to save an analysis configuration for
future use, you can specify a file name using the Browse button or by entering a directory and file name into the Save As field (see Figure 24). It is
recommended that you give these configuration files a “.cfg” extension so you
can recognize them later. Only the elements of the Analysis Configuration for
which the Save? checkbox is activated will be saved. If you highlight multiple rows and click the Select button, the Save? checkbox for those rows will be activated. Alternatively, if you highlight multiple rows
and click the Clear button, the Save? checkbox will be turned off. Once
you have saved an analysis configuration, you can use it later in EmisView to
create a custom Product.
Figure 24. Analysis Configuration
7. Products
Products in EmisView control how the results of an Analysis are presented. The functions available on the Products tab are very similar to those available from the other tabs. The Products tab is shown in Figure 25. These include the buttons on the toolbar above the table of Products, and the buttons New, Copy, Rename, Delete, Configure, and Help. See the appropriate sections of the Datasets tab discussion for descriptions of the functions that are common between the Datasets and Products tabs.
Figure 25. Product Editor

Currently, there is a single default product provided with EmisView called “Table and Plots”. When an Analysis is run, this causes the Analysis Results window as discussed above to appear. Eventually, there will be additional types of products, such as Maps and Comparisons. These will be added to the list of default products. In the meantime, with the current version of EmisView, it is still possible to define a custom product by specifying an Analysis Configuration in the Product Editor.
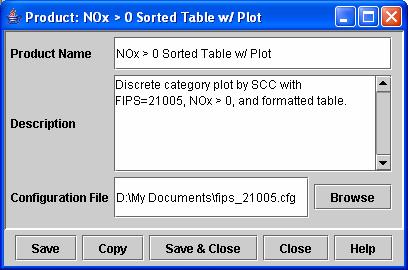
To create a custom Product, from the EmisView Products tab on the Main GUI select the checkbox next to the Table and Plots and then click the Configure button. The Product Editor window for the Table and Plots Product will appear (see Figure 26). You cannot edit many of the fields for the Table and Plots Product because it is defined by EmisView... However, you can click the Copy button to create a copy of the product, which you can then customize. After clicking Copy, you will be prompted to give a name for the new product and then a new Product Editor window will appear that allows you to edit the fields. From this window (see Figure 27), you should enter a descriptive Product Name and Description for the custom Product. Then click Browse and select a previously saved Analysis Configuration file. Once you click Save or Save & Close, your new product will appear in the list of products that can be selected for an Analysis on the Analysis Editor window. Keep in mind that you can apply the product only to Analyses that have the same data columns that are referenced in the analysis configuration.
Figure 26. Table and Plots Default Product
Editor
Figure 27. Customized Product Editor
To perform an Analysis using your custom Product, select it as the Product to use on the Analysis Editor. The Analysis Results table (see example in Figure 19) should appear, with any sort, filter, and format settings already applied. To see the plots that were included in the configuration, click the Analysis Configuration icon and from the Analysis Configuration dialog (similar to the one on Figure 24), select the plots you wish to see and click the View button.